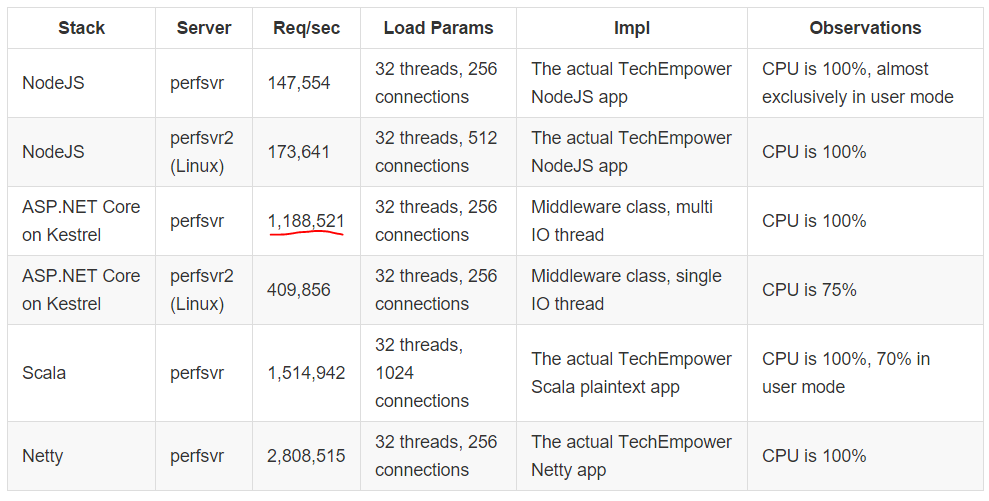
> How do we structure our solution?
> What do we name our files?
> How do we organize the folders in the project?
> How do we structure our code regions?
It’s probably safe to say we’ve all sat with these questions and still do every time we expand our projects or create new ones.
The big question that this article addresses is whether we should organize our code based on the “Domain” or rather on “Technical” implementations.
Let’s quickly define both and see which is better.
Technical Focus
This approach organizes code with a technical or functional focus. This is a more traditional way of organizing an application, but still very much in use today. Let’s see how this would look practically
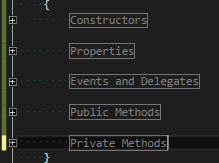
Code Regions
Regions are defined according to the functional implementation. If it’s a method and it’s public it goes to Public Methods, regardless of what the method does.
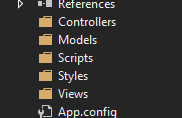
Project Layout
For example creating and MVC application, File -> New Project lays out the folders with a technical focus. If you create a View, regardless of what it does, it goes into the Views folder.
Solution Architecture
The traditional layered architecture is a very common practice. This approach organizes the projects according to the function. If I have a Business Logic or Service class, it will go into the Domain project, regardless of what it does.

In short it’s a “What it IS” approach
You’ll see that in each of the above cases, we’ve organised according to what something IS and not what it DOES. So if we’re developing a Hospital application, a Restaurant Management system, or even a Live Sport Scoring dashboard, the structure for these vastly different domains will look almost identical.
Domain Focus
This approach organizes code with a domain or business focus. The focus on the domain has definitely been popularized by designs such as DDD, TDD, SOA, Microservices etc. Let’s see how this would look practically:
Code Regions
Regions are defined according to the domain implementation. Anything related to “Admitting a patient to the Hospital” will go in the Admit Patient region, regardless of what it is.
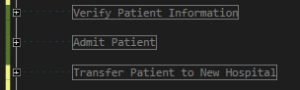
Project Layout
Taking the MVC example mentioned earlier for Project Layout, we would now see folders according to the specific domain. If we create something that is related to “customer feedback”, it would go in the CustomerFeedback folder, regardless of what it is (view, controller, script etc.)
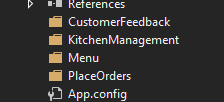
Solution Architecture
Architecture would be based around a type of SOA or Microservices approach, where each domain would exist independently in it’s own project. If we have new domain in a live sport scoring app such as “Cricket”, we would create a new project for Cricket and everything related to it will go in there regardless of what it is.
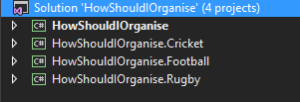
In short it’s a “What it DOES” approach
You’ll see that in each of the above cases, we’ve organised according to what something DOES and not what it IS. So once again, if we’re developing a Hospital application, a Restaurant Management system and a Live Sport Scoring dashboard, the structure for these vastly different domains will look completely different.
So which is best?
Firstly let’s just put it out there that there’s a “3rd approach” as well, a hybrid between the 2. For example, we could have a Properties region (which is technical), and then a Admit Patient region (which is domain) for all domain related methods.
So which is best? Well let’s see…
Why Technical is better than Domain
1. Every project’s layout and all page regions are identical.
We as developers are often very technically oriented, so this would feel right at home as we can feel in control even if we’re clueless about the domain.
2. Less pieces
Since there are only so many technicalities within a project, once we’ve grouped by them, the number of regions, folders or projects will never grow.
3. Layer specific skills or roles
If the development team’s roles in a project are technical-specific, this approach is great. Each developer has their specific folder or project which they work on and maintain. For example you have one developer only creating views, another only doing domain specific validations, another only focusing on data access etc.
Why Domain is better than Technical
1. We’re solving business problems
As technical as we developers can be, at the end of the day, if we’re not solving domain specific problems, we’re failing as software developers. Since business is our core and the technical only the tool to get us there, organizing code, folder and projects by domain makes much more sense.
2. Scales better
When the application expands or the scope widens, it often means that the new implementations don’t affect or bloat existing code as each domain is “isolated” from the next (closer adherence to the Single Responsibility and Open/closed principles).
3. Everything is together
Often developers are responsible for all or at least most layers of technical implementations. If we for instance had to now expand our Live Sport Scoring web dashboard to include tennis, we very easily end up working with data access code, business rules and validations, view models, views, scripts, styles, controllers etc. and these are for a typical web application implementation. We could easily have a few more.
The point is, we often work with all of these while solving a single domain problem. So if we for example have a tennis folder and our tennis specific scripts, styles, views, controllers etc. were together, that would already be much more productive.
4. Reusable
This only really affects architecture, but if a project is built and isolated by domain, it become reusable by different applications on it’s own. In an enterprise environment, this is really useful.
For example if a large corporate business has internal procurement rules or procedures, but the business has many different systems for it’s departments, be it the cafeteria, HR, finances etc. then an SOA-type approach would enable you to have one project which handles all the procurement procedures and all the different flavours of applications can go through this procurement service, ensure that both the correct procedures and the same procedures are used for every procurement for every department.
Conclusion
So I haven’t yet said which one is best. For me personally, my bias definitely lies more with organizing projects around the domain.
Once again, this is no silver bullet answer or solution, but remember that there are most definitely the wrong approach for a specific project or problem. Here are some questions that we should ask, testing our approach to existing systems:
- Are there any areas where we suffer under lack of productivity?
- If so, would the different approach be better?
- If so, would changing the approach be too great an adjustment for the benefits it would provide?
But the ultimate questions really are:
- Are the business needs currently being met?
- And are the developers happy and in consensus with the approach?
As the good old saying goes: “Don’t fix something that’s not broken”.
I’d love to hear thoughts from your experience with either approach and any opinions, short falls or benefits you’ve experienced